Examples of permutation-invariant reinforcement learning agents
The Sensory Neuron as a Transformer: Permutation-Invariant Neural Networks for Reinforcement Learning
Abstract
In complex systems, we often observe complex global behavior emerge from a collection of agents interacting with each other in their environment, with each individual agent acting only on locally available information, without knowing the full picture. Such systems have inspired development of artificial intelligence algorithms in areas such as swarm optimization and cellular automata. Motivated by the emergence of collective behavior from complex cellular systems, we build systems that feed each sensory input from the environment into distinct, but identical neural networks, each with no fixed relationship with one another. We show that these sensory networks can be trained to integrate information received locally, and through communication via an attention mechanism, can collectively produce a globally coherent policy. Moreover, the system can still perform its task even if the ordering of its inputs is randomly permuted several times during an episode. These permutation invariant systems also display useful robustness and generalization properties that are broadly applicable.
Introduction
Sensory substitution refers to the brain's ability to use one sensory modality (e.g., touch) to supply environmental information normally gathered by another sense (e.g., vision). Numerous studies have demonstrated that humans can adapt to changes in sensory inputs, even when they are fed into the wrong channels
A permutation invariant network performing CartpoleSwingupHarder. Shuffle the order of the 5 observations at any time, and see how the agent adapts to the new ordering of the observations.
Modern deep learning systems are generally unable to adapt to a sudden reordering of sensory inputs, unless the model is retrained, or if the user manually corrects the ordering of the inputs for the model. However, techniques from continual meta-learning, such as adaptive weights
In this work, we investigate agents that are explicitly designed to deal with sudden random reordering of their sensory inputs while performing a task. Motivated by recent developments in self-organizing neural networks
In our experiments, we find that each individual sensory neural network module, despite receiving only localized information, can still collectively produce a globally coherent policy, and that such a system can be trained to perform tasks in several popular reinforcement learning (RL) environments. Furthermore, our system can utilize a varying number of sensory input channels in any randomly permuted order, even when the order is shuffled again several times during an episode.
Permutation invariant systems have several advantages over traditional fixed-input systems. We find that encouraging a system to learn a coherent representation of a permutation invariant observation space leads to policies that are more robust and generalizes better to unseen situations. We show that, without additional training, our system continues to function even when we inject additional input channels containing noise or redundant information. In visual environments, we show that our system can be trained to perform a task even if it is given only a small fraction of randomly chosen patches from the screen, and at test time, if given more patches, the system can take advantage of the additional information to perform better. We also demonstrate that our system can generalize to visual environments with novel background images, despite training on a single fixed background. Lastly, to make training more practical, we propose a behavioral cloning scheme to convert policies trained with existing methods into a permutation invariant policy with desirable properties.
Method
Background
Our goal is to devise an agent that is permutation invariant (PI) in the action space to the permutations in the input space. While it is possible to acquire a quasi-PI agent by training with randomly shuffled observations and hope the agent's policy network has enough capacity to memorize all the patterns, we aim for a design that achieves true PI even if the agent is trained with fix-ordered observations. Mathematically, we are looking for a non-trivial function such that for any , and is any permutation of the indices . A different but closely related concept is permutation equivariance (PE) which can be described by a function such that . Unlike PI, the dimensions of the input and the output must equal in PE.
Self-attentions can be PE. In its simplest form, self-attention is described as where are the Query, Key and Value matrices and is a non-linear function. In most scenarios, are functions of the input (e.g. linear transformations), and permuting therefore is equivalent to permuting the rows in and based on its definition it is straightforward to verify the PE property. Set Transformer
Here, we provide a simple, non-rigorous example demonstrating permutation invariant property of the self-attention mechanism, to give some intuition to readers who may not be familiar with self-attention. For a detailed treatment, please refer to
As mentioned earlier, in its simplest form, self-attention is described as:
where are the Query, Key and Value matrices and is a non-linear function. In this work, is a fixed matrix, and are functions of the input where is the number of observation components (equivalent to the number of sensory neurons) and is the dimension of each component. In most settings, are linear transformations, thus permuting therefore is equivalent to permuting the rows in .
We would like to show that the output is the same regardless of the ordering of the rows of . For simplicity, suppose , , , so that , , :
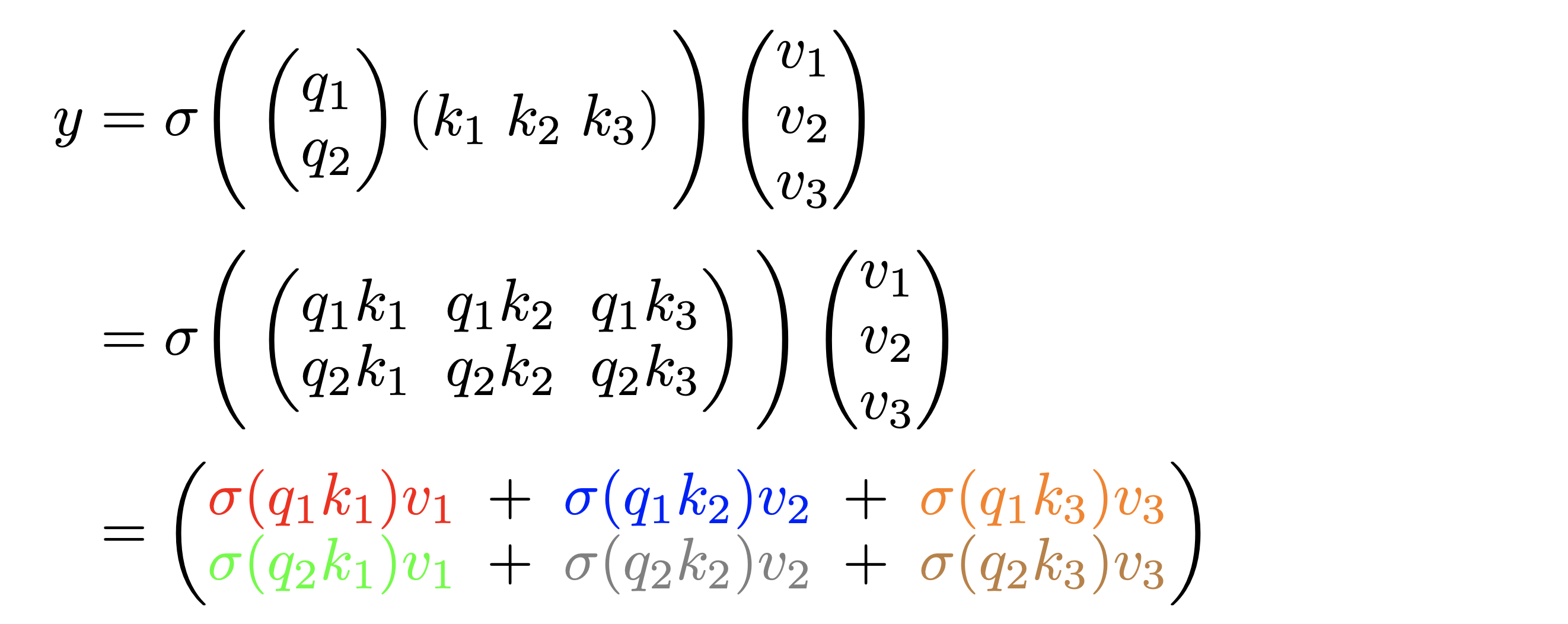
The output remains the same when the rows of are permuted from to :
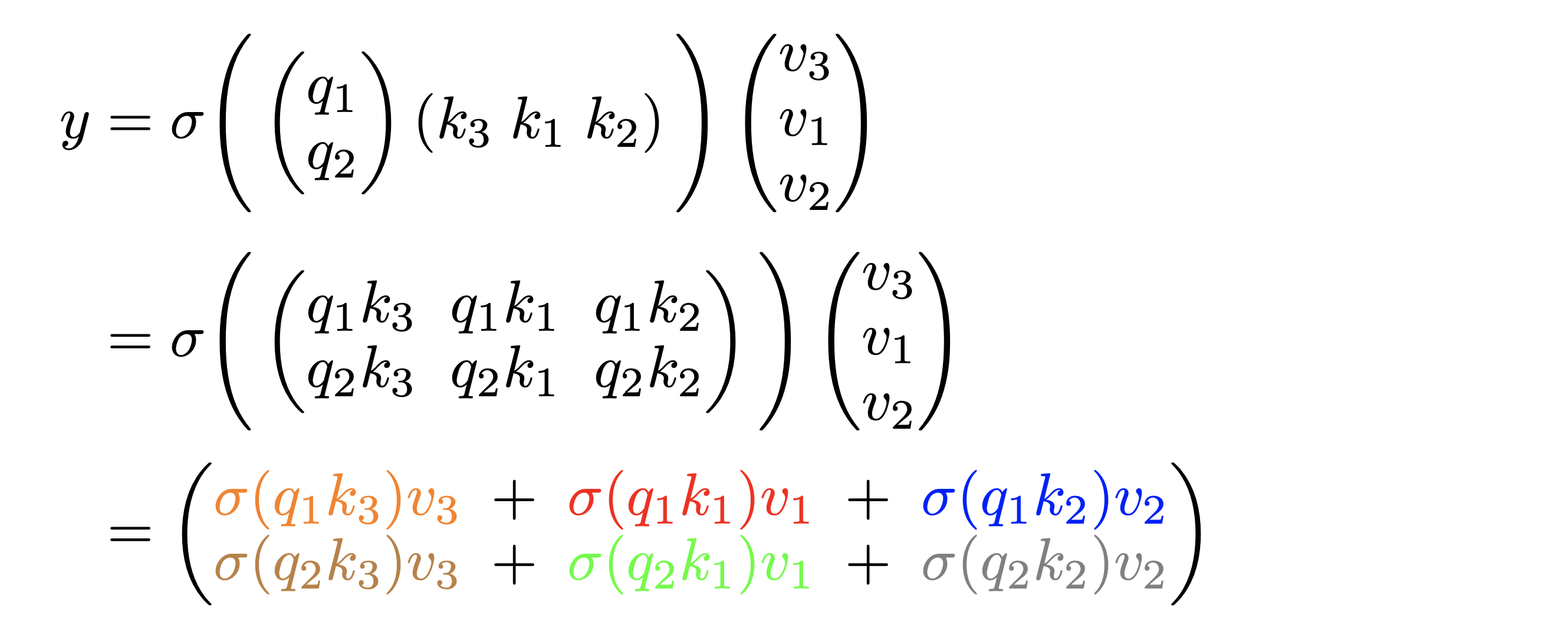
We have highlighted the same terms with the same color in both equations to show the results are indeed identical. In general, we have . Permuting the input is equivalent to permuting the indices (i.e. rows of and ), which only affects the order of the outer summation and does not affect because summation is a permutation invariant operation. Notice that in the above example and the proof here we have assumed that is an element-wise operation--a valid assumption since most activation functions satisfy this condition.
As we'll discuss next, this formulation lets us convert an observation signal from the RL environment into a permutation invariant representation . We'll use this representation in place of the actual observation as the input that goes into the downstream policy network of an RL agent.
Sensory Neurons with Attention
To create permutation invariant (PI) agents, we propose to add an extra layer in front of the agent's policy network , which accepts the current observation and the previous action as its inputs. We call this new layer AttentionNeuron, and the following figure gives an overview of our method:
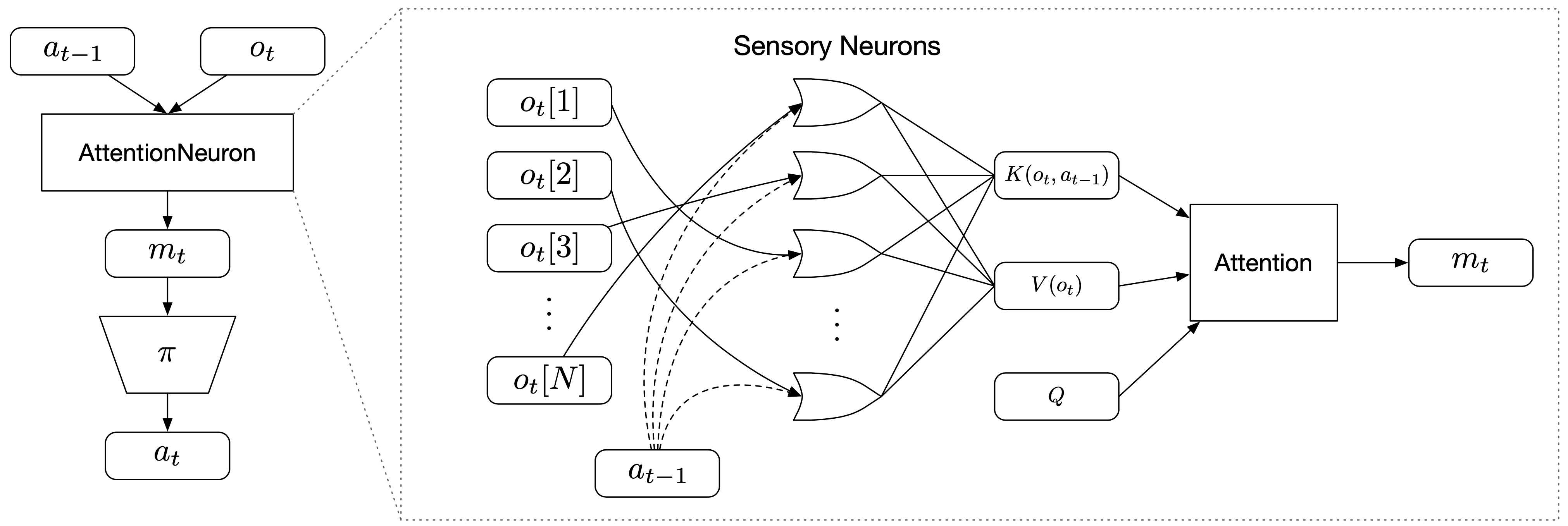
AttentionNeuron is a standalone layer, in which each sensory neuron only has access to a part of the unordered observations . Together with the agent's previous action , each neuron generates messages independently using the shared functions and . The attention mechanism summarizes the messages into a global latent code .
The operations inside AttentionNeuron can be described by the following two equations:
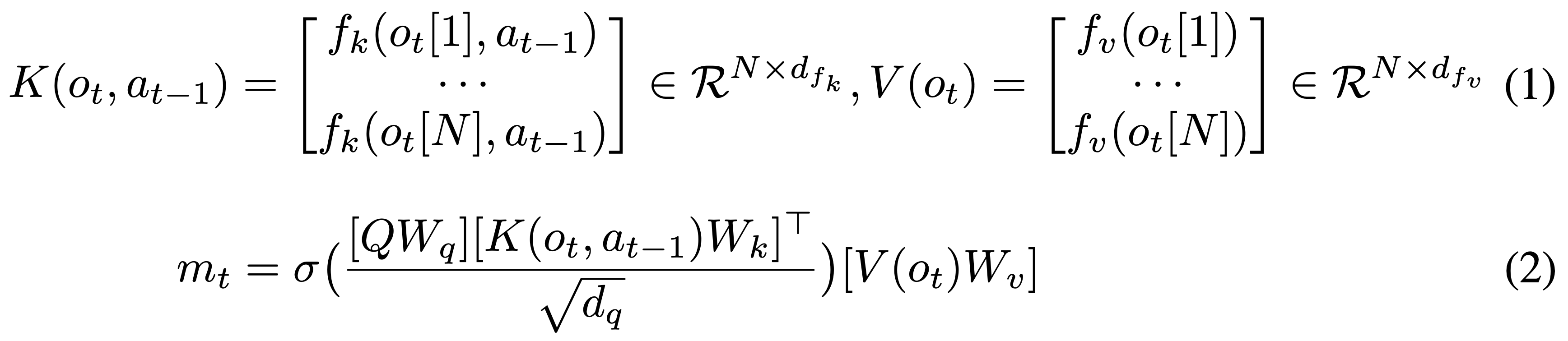
Equation 1 shows how each of the sensory neuron independently generates its messages and , which are functions shared across all sensory neurons. Equation 2 shows the attention mechanism aggregate these messages. Note that although we could have absorbed the projection matrices into , we keep them in the equation to show explicitly the formulation. Equation 2 is almost identical to the simple definition of self-attention mentioned earlier. Following
Note that permuting the observations only affects the row orders of and , and that applying the same permutation to the rows of both and still results in the same which is PI. As long as we set constant the number of rows in , the change in the input size affects only the number of rows in and and does not affect the output . In other words, our agent can accept inputs of arbitrary length and output a fixed sized . Later, we apply this flexibility of input dimensions to RL agents.
For clarity, the following table summarizes the notations as well as the corresponding setups we used for the experiments:
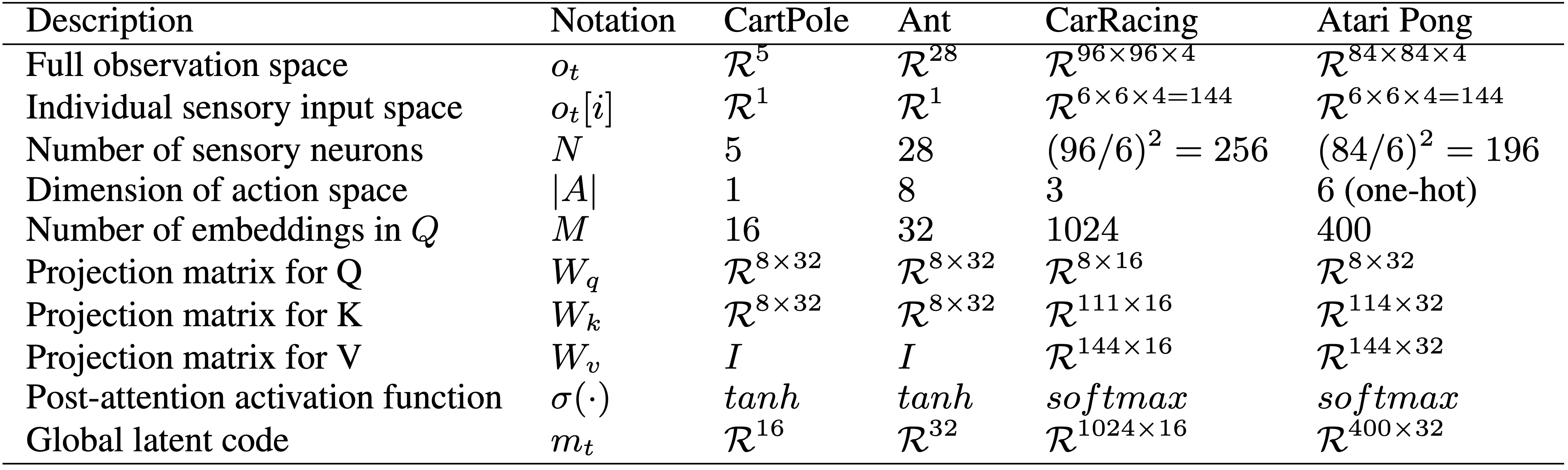
In this table, we also provide the dimensions used in our model for different RL environments, to give the reader a sense of the relative magnitudes involved in each part of the system.
Design Choices
It is worthwhile to have a discussion on the design choices made. Since the ordering of the input is arbitrary, each sensory neuron is required to interpret and identify their received signal. To achieve this, we want to have temporal memories. In practice, we find both RNNs and feed-forward neural networks (FNN) with stacked observations work well, with FNNs being more practical for environments with high dimensional observations.
In addition to the temporal memory, including previous actions is important for the input identification too. Although the former allows the neurons to infer the input signals based on the characteristics of the temporal stream, this may not be sufficient. For example, when controlling a legged robot, most of the sensor readings are joint angles and velocities from the legs, which are not only numerically identically bounded but also change in similar patterns. The inclusion of previous actions gives each sensory neuron a chance to infer the casual relationship between the input channel and the applied actions, which helps with the input identification.
Finally, in Equation 2 we could have combined as a single learnable parameters matrix, but we separate them for two reasons.
First, by factoring into two matrices, we can reduce the number of learnable parameters.
Second, we find that instead of making learnable, using the positional encoding proposed in Transformer
Experiments
We experiment on several different RL environments to study various properties of permutation invariant RL agents. Due to the nature of the underlying tasks, we will describe the different architectures of the policy networks used and discuss various training methods. However, the AttentionNeuron layers in all agents are similar, so we first describe the common setups. Hyper-parameters and other details for all experiments are summarized in the Appendix.
For non-vision continuous control tasks, the agent receives an observation vector at time . We assign sensory neurons for the tasks, each of which sees one element from the vector, hence . We use an LSTM
For vision based tasks, we gray-scale and stack consecutive RGB frames from the environment, and thus our agent observes .
is split into non-overlapping patches of size using a sliding window, so each sensory neuron observes .
Here, flattens the data and returns it, hence returns a tensor of shape . Due to the high dimensionality for vision tasks, we do not use RNNs for , but instead use a simpler method to process each sensory input. takes the difference between consecutive frames (), then flattens the result, appends , and returns the concatenated vector. thus gives a tensor of shape (111 for CarRacing and 114 for Atari Pong). We use softmax as the non-linear activation function , and we apply layer normalization
Cart-pole swing up
We examine Cart-pole swing up
In this demo, the user can shuffle the order of the 5 inputs at any time, and observe how the agent adapts to the new ordering of the inputs.
We use a two-layer neural network as our agent. The first layer is an AttentionNeuron layer with sensory neurons and outputs . A linear layer takes as input and outputs a scalar action. For comparison, we also trained an agent with a two-layer FNN policy with hidden units. We use direct policy search to train agents with CMA-ES
We report experimental results in the following table:

For each experiment, we report the average score and the standard deviation from 1000 test episodes. Our agent is trained only in the environment with 5 sensory inputs.
Our agent can perform the task and balance the cart-pole from an initially random state.
Its average score is slightly lower than the baseline (See column 1) because each sensory neuron requires some time steps in each episode to interpret the sensory input signal it receives. However, as a trade-off for the performance sacrifice, our agent can retain its performance even when the input sensor array is randomly shuffled, which is not the case for an FNN policy (column 2).
Moreover, although our agent is only trained in an environment with five inputs, it can accept an arbitrary number of inputs in any order without re-training.
The AttentionNeuron layer should possess 2 properties to attain these: its output is permutation invariant to its input, and its output carries task-relevant information. The following figure is a visual confirmation of the permutation invariant property, whereby we plot the output messages from the layer and their changes over time from two tests. Using the same environment seed, we keep the observation as-is in the first test but we shuffle the order in the second. As the figure shows, the output messages are identical in the two roll-outs.
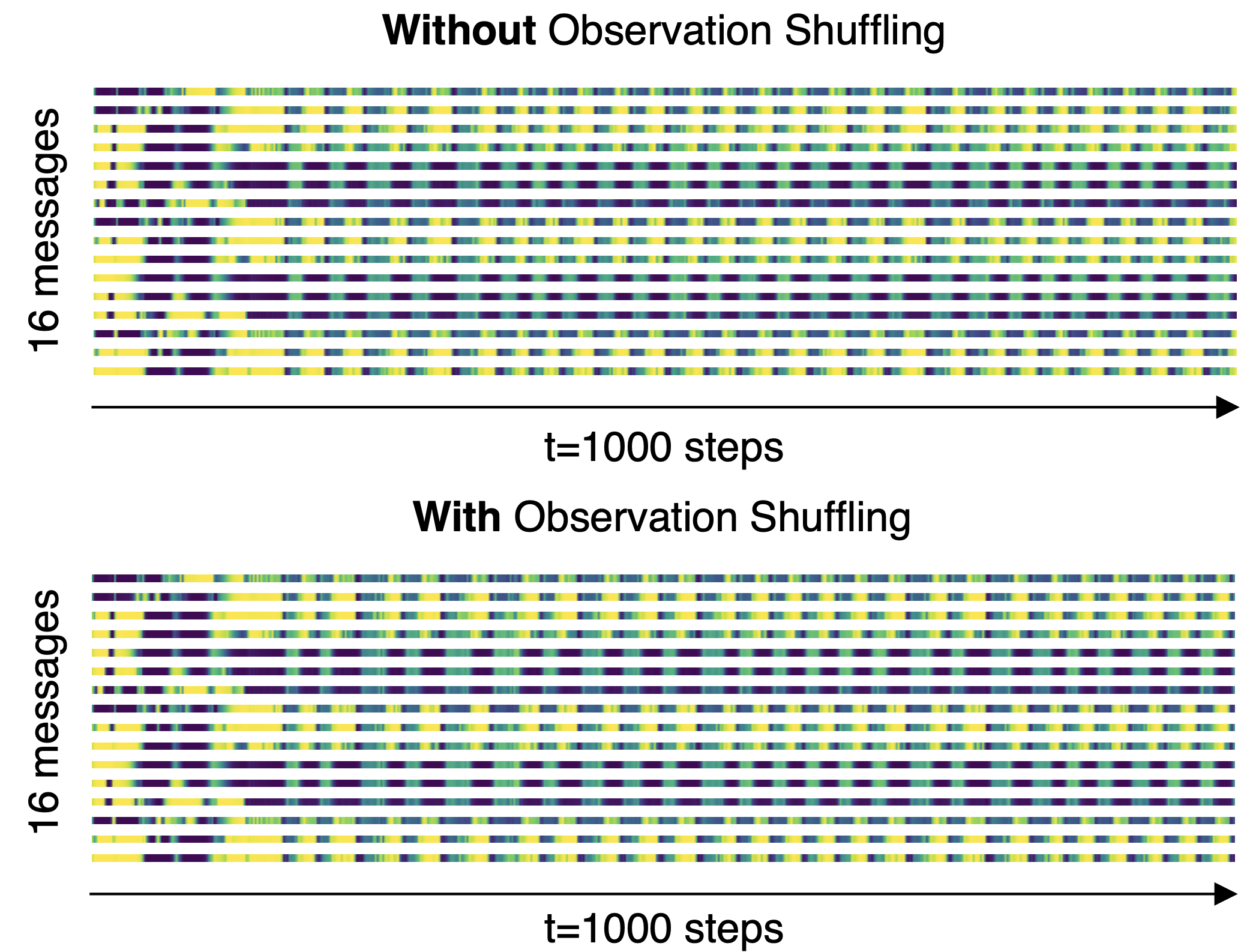
The output (16-dimensional global latent code) from the AttentionNeuron layer does not change when we input the sensor array as-is (top) or when we randomly shuffle the array (bottom). Yellow represents higher values, and blue for lower values.
We also perform a simple linear regression analysis on the outputs (based on the shuffled inputs) to recover the 5 inputs in their original order.
The following table shows the values

For each of the sensory inputs we have one LR model with as the explanatory variables.
Finally, to accompany the quantitative results in this section, we extended the earlier interactive demo to showcase the flexibility of PI agents. Here, our agent, with no additional training, receives 15 input signals in shuffled order, ten of which are pure noise, and the other five are the actual observations from the environment.
Without additional training, our agent receives 15 input signals in shuffled order, 10 of which are pure Gaussian noise (σ=0.1), and the other 5 are the actual observations from the environment. Like the earlier demo, the user can shuffle the order of the 15 inputs, and observe how the agent adapts to the new ordering of the inputs.
The existing policy is still able to perform the task, demonstrating the system's capacity to work with a large number of inputs and attend only to channels it deems useful. Such flexibility may find useful applications for processing a large unspecified number of signals, most of which are noise, from ill-defined systems.
PyBullet Ant
While direct policy search methods such as evolution strategies (ES) can train permutation invariant RL agents, oftentimes we already have access to pre-trained agents or recorded human data performing the task at hand. Behavior cloning (BC) can allow us to convert an existing policy to a version that is permutation invariant with desirable properties associated with it. We report experimental results here:
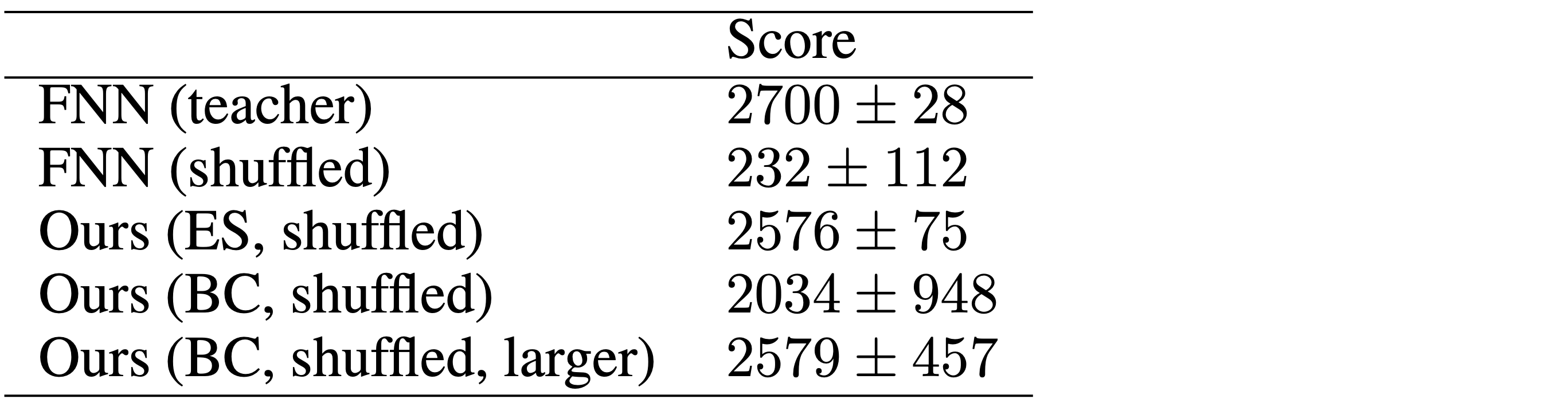
We train a standard two-layer FNN policy to perform AntBulletEnv-v0, a 3D locomotion task in PyBullet
The performance of the BC agent is lower than the one trained from scratch with ES, despite having the identical architecture. This suggests that the inductive bias that comes with permutation invariance may not match the original teacher network, so the small model used here may not be expressive enough to clone any teacher policy, resulting in a larger variance in performance. A benefit of gradient-based BC, compared to RL, is that we can easily train larger networks to fit the behavioral data. We show that increasing the size of the subsequent layers for BC does enhance the performance.
While not explicitly trained to do so, we note that the policy still works even when we reshuffle the ordering of the observations several times during an episode:
The ordering of the 28 observations is reshuffled every 100 frames.
As we will demonstrate next, BC is a useful technique for training permutation invariant agents in environments with high dimensional visual observations that may require larger networks.
Atari Pong
Here, we are interested in solving screen-shuffled versions of vision-based RL environments, where each observation frame is divided up into a grid of patches, and like a puzzle, the agent must process the patches in a shuffled order to determine a course of action to take. A shuffled version of Atari Pong
But rather than throwing away the spatial structure entirely from our solution, we find that convolution neural network (CNN) policies work better than fully connected multi-layer perceptron (MLP) policies when trained with behavior cloning for Atari Pong. In this experiment, we reshape the output of the AttentionNeuron layer from to , a 2D grid of latent codes, and pass this 2D grid into a CNN policy. This way, the role of the AttentionNeuron layer is to take a list of unordered observation patches, and learn to construct a 2D grid representation of the inputs to be used by a downstream policy that expects some form of spatial structure in the codes. Our permutation invariant policy trained with BC can consistently reach a perfect score of 21, even with shuffled screens. The details of the CNN policy and BC training can be found in the Appendix.
Unlike typical CNN policies, our agent can accept a subset of the screen, since the agent's input is a variable-length list of patches. It would thus be interesting to deliberately randomly discard a certain percentage of the patches and see how the agent reacts. The net effect of this experiment for humans is similar to being asked to play a partially occluded and shuffled version of Atari Pong. During training via BC, we randomly remove a percentage of observation patches. In tests, we fix the randomly selected positions of patches to discard during an entire episode. The following figure demonstrates the agent's effective policy even when we also remove 70% of the patches:
We present the results in a heat map in the following figure, where the y-axis shows the patches removed during training and the x-axis gives the patch occlusion ratio in tests:
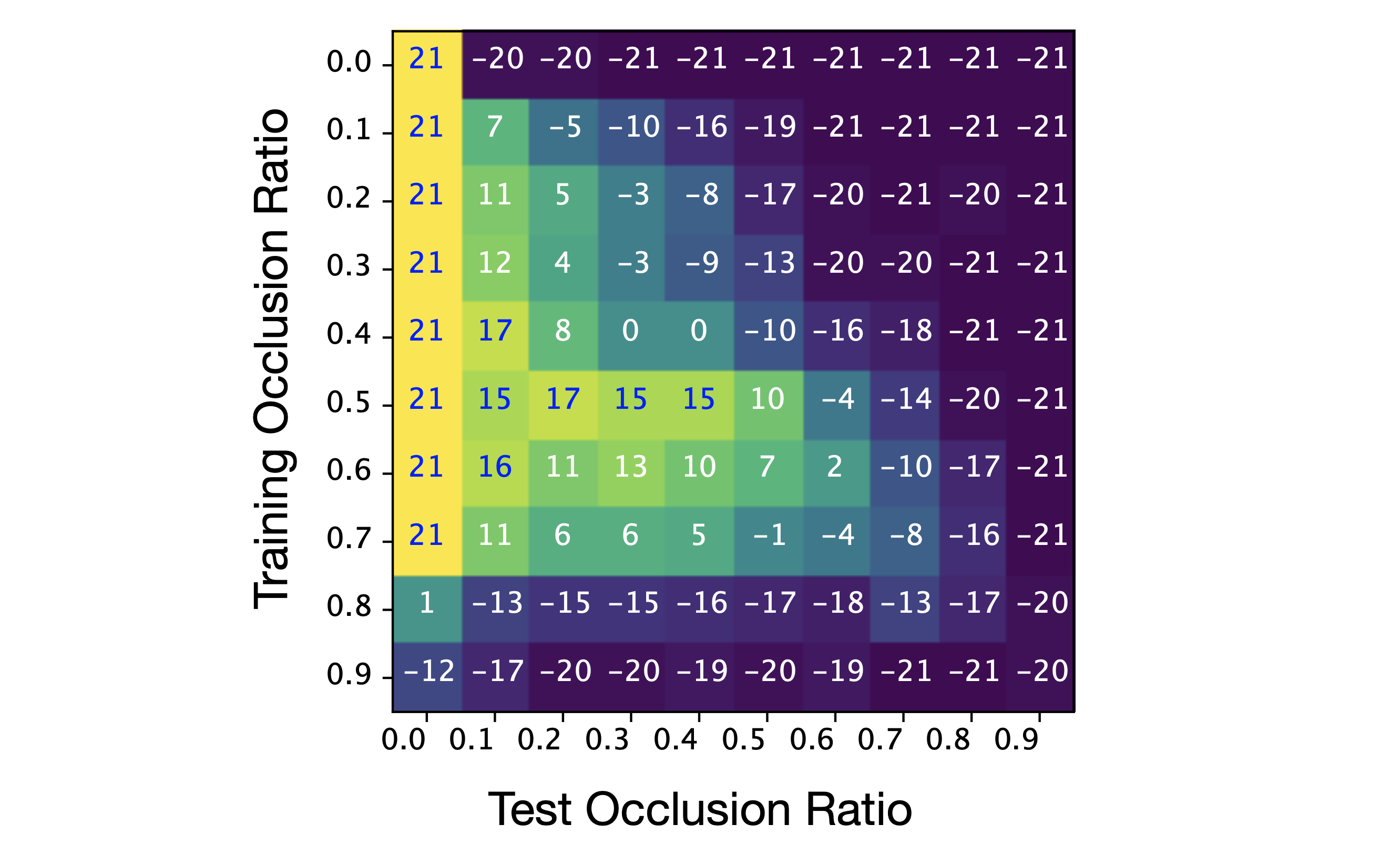
Mean test scores in Atari Pong, and example of a randomly-shuffled occluded observation.} In the heat map, each value is the average score from 100 test episodes.
The heat map shows clear patterns for interpretation. Looking horizontally along each row, the performance drops because the agent sees less of the screen which increases the difficulty. Interestingly, an agent trained at a high occlusion rate of rarely wins against the Atari opponent, but once it is presented with the full set of patches during tests, it is able to achieve a fair result by making use of the additional information.
To gain insights into understanding the policy, we projected the AttentionNeuron layer's output in a test roll-out to 2D space using t-SNE
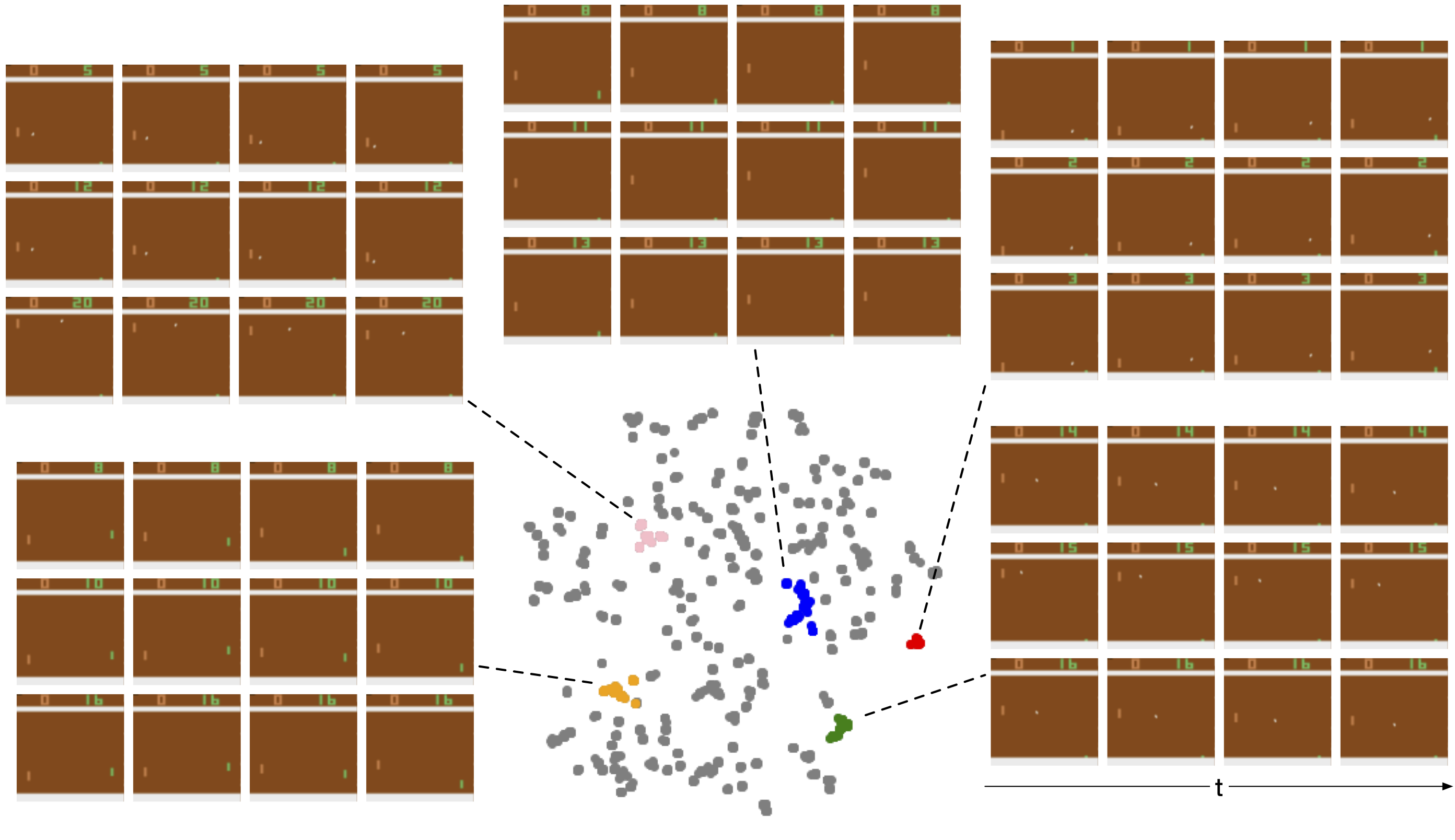
We highlight several representative groups in the plot, and show the sampled inputs from them. For each group, we show 3 corresponding inputs (rows) and unstack each to show the time dimension (columns).
For example, the 3 sampled inputs in the blue group show the situation when the agent's paddle moved toward the bottom of the screen and stayed there. Similarly, the orange group shows the cases when the ball was not in sight, this happened right before/after a game started/ended. We believe these discriminative outputs enabled the downstream policy to accomplish the agent's task.
Car Racing
Our agent is only trained on this environment. The right screen is what our agent observes and the left is for human visualization. A human will find driving with the shuffled observation to be very difficult because we are not constantly exposed to such tasks, just like in the “reverse bicycle” example mentioned earlier.
We find that encouraging an agent to learn a coherent representation of a deliberately shuffled visual scene leads to agents with useful generalization properties.
Such agents are still able to perform their task even if the visual background of the environment changes, despite being trained only on a single static background.
Out-of-domain generalization is an active area, and here, we combine our method with AttentionAgent
As mentioned, we combine the AttentionNeuron layer with the policy network used in AttentionAgent. As the hard-attention-based policy is non-differentiable, we train the entire system using ES.
We reshape the AttentionNeuron layer's outputs to adapt for the policy network.
Specifically, we reshape the output message to such that it can be viewed as a 32-by-32 grid of 16 channels.
The end result is a policy with two layers of attention: the first layer outputs a latent code book to represent a shuffled scene, and the second layer performs hard attention to select the top codes from a 2D global latent code book. A detailed description of the selective hard attention policy from
We first train the agent in the CarRacing

Without additional training or fine-tuning, we test whether the agent can also navigate in four modified environments where the green grass background is replaced with various images. In the CarRacing Test Result (from column 2) shows, our agent generalizes well to most of the test environments with only mild performance drops while the baseline method fails to generalize. We suspect this is because the AttentionNeuron layer has transformed the original RGB space to a useful hidden representation (represented by ) that has eliminated task irrelevant information after observing and reasoning about the sequences of during training, enabling the downstream hard attention policy to work with an optimized abstract representation tailored for the policy, instead of raw RGB patches.
We also compare our method to NetRand
Our score on the base CarRacing task is lower than NetRand, but this is expected since our agent requires some amount of time steps to identify each of the inputs (which could be shuffled), while the NetRand and AttentionAgent agent will simply fail on the shuffled versions of CarRacing. Despite this, our method still compares favorably on the generalization performance.
To gain some insight into how the agent achieves its generalization ability, we visualize the attentions from the AttentionNeuron layer in the following figure:
We highlight the patches that receive the most attention.
Top: Attention plot in training environment.
Bottom: Attention plot in a test environment with unseen background.
In CarRacing, the agent has learned to focus its attention (indicated by the highlighted patches) on the road boundaries which are intuitive to human beings and are critical to the task. Notice that the attended positions are consistent before and after the shuffling. This type of attention analysis can also be used to analyze failure cases too. More details about this visualization can be found in the Appendix.
Related Work
Our work builds on ideas from various different areas:
Self-organization is a process where some form of global order emerges from local interactions between parts of an initially disordered system.
It is also a property observed in cellular automata (CA)
Using modern deep learning tools, recent work demonstrates that neural CA, or self-organized neural networks performing only local computation, can generate (and re-generate) coherent images
Meta-learning recurrent neural networks (RNN)
In contrast, the system presented here does not use an error or reward signal to meta-learn or fine-tune its policy. But rather, by using the shared modular building blocks from the meta-learning literature, we focus on learning or converting an existing policy to one that is permutation invariant, and we examine the characteristics such policies exhibit in a zero-shot setting, without additional training.
Attention can be viewed as an adaptive weight mechanism that alters the weight connections of a neural network layer based on what the inputs are. Linear dot-product attention has first been proposed for meta-learning
Attention mechanisms have found many uses for RL
Discussion and Future Work
In this work, we investigate the properties of RL agents that can treat their observations as an arbitrarily ordered, variable-length list of sensory inputs. By processing each input stream independently, and consolidating the processed information using attention, our agents can still perform their tasks even if the ordering of the observations is randomly permuted several times during an episode, without explicitly training for frequent re-shuffling. We report results of performance versus shuffling frequency in the following table for each environment:
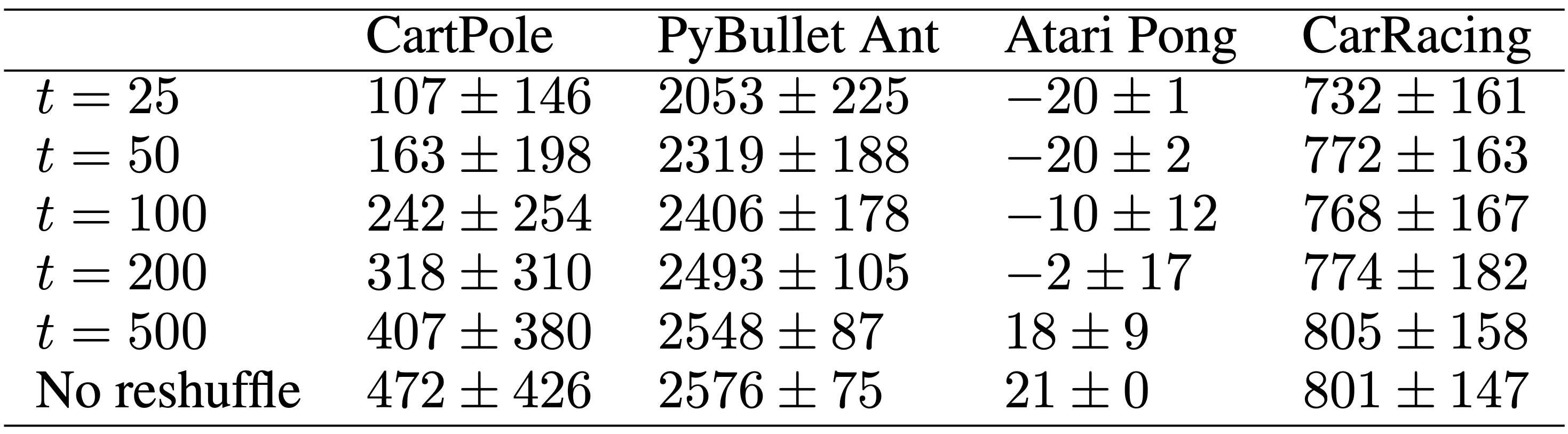
In each test episode, we reshuffle the observations every t steps. For CartPole, we test for 1000 episodes because of its larger task variance. For the other tasks, we report mean and standard deviation from 100 tests. All environments except for Atari Pong have a hard limit of 1000 time steps per episode. In Atari Pong, while the maximum length of an episode does not exist, we observed that an episode usually lasts for around 2500 steps.
Applications By presenting the agent with shuffled, and even incomplete observations, we encourage it to interpret the meaning of each local sensory input and how they relate to the global context. This could be useful in many real world applications. For example, such policies could avoid errors due to cross-wiring or complex, dynamic input-output mappings when being deployed in real robots. A similar setup to the CartPole experiment with extra noisy channels could enable a system that receives thousands of noisy input channels to identify the small subset of channels with relevant information.
Limitations For visual environments, patch size selection will affect both performance and computing complexity. We find that patches of 6x6 pixels work well for our tasks, as did 4x4 pixels to some extent, but single pixel observations fail to work. Small patch sizes also result in a large attention matrix which may be too costly to compute, unless approximations are used
Another limitation is that the permutation invariant property applies only to the inputs, and not to the outputs. While the ordering of the observations can be shuffled, the ordering of the actions cannot. For permutation invariant outputs to work, each action will require feedback from the environment, including reward information, in order to learn the relationship between itself and the environment.
Societal Impact Like most algorithms proposed in computer science and machine learning, our method can be applied in ways that will have potentially positive or negative impacts to society. While our small-scale, self-contained experiments study only the properties of RL agents that are permutation invariant to their observations, and we believe our results do not directly cause harm to society, the robustness and flexible properties of the method may be of use for data-collection systems that receive data from a large variable number of sensors. For instance, one could apply permutation invariant sensory systems to process data from millions of sensors for anomaly detection, which may lead to both positive or negative impacts, if used in applications such as large-scale sensor analysis for weather forecasting, or deployed in large-scale surveillance systems that could undermine our basic freedoms.
Our work also provides a way to view the Transformer
Future Work An interesting future direction is to also make the action layer have the same properties, and model each motor neuron as a module connected using attention. With such methods, it may be possible to train an agent with an arbitrary number of legs, or control robots with different morphology using a single policy that is also provided with a reward signal as feedback. Moreover, our method accepts previous actions as a feedback signal in this work. However, the feedback signal is not restricted to the actions. We look forward to seeing future works that include signals such as environmental rewards to train permutation invariant meta-learning agents that can adapt to not only changes in the observed environment, but also to changes to itself.
If you would like to discuss any issues or give feedback, please visit the GitHub repository of this page for more information.
 Neuron icon by artist
Neuron icon by artist